6 Best Ways to Scale Your Systems
If someone gave you €100, would you take it? No hidden agendas, no complicated schemes, no tricks. What about €1000? €10000? It would be silly not to take it, right? When willing-to-pay customers come to your business, and you refuse them because "there's just too many of them", that's when you know you have a problem! It's time to scale. And better do it quickly!
There are plenty of problems to tackle when scaling businesses. Those are good problems, though - they mean you're doing things right. However, for many companies, scaling their systems to meet increased customer demand usually also means scaling their systems. Here are the six best ways to do it right.
1. Splitting Services
Splitting large monolithic software projects into smaller ones is not a new concept. It was introduced as SOA (Service-Oriented Architecture) and later evolved into architecture known as Microservices. Breaking the functionality into multiple services can drastically improve performance and scalability and reduce costs. Rather than scaling the whole system, we can scale the most problematic services. Each service can utilize the most optimal for the job architecture, programming language, and data stores. Moreover, we can host those services on separate machines that are just good enough instead of hosting them on a single state-of-the-art powerhouse, which tends to make things cheaper. These benefits, together with reduced source code complexity, improved fault isolation, and faster deployments, often make splitting services a no-brainer for huge organizations.
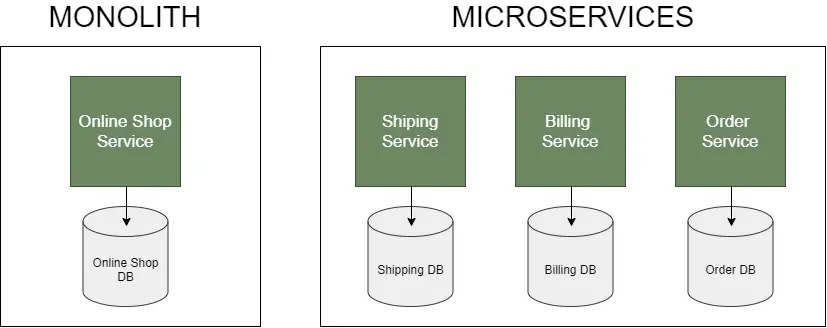
There are a couple of things to consider before starting with Microservices. Microservices-based architecture introduces a new set of problems. While these days the most prominent players in the game are using this architecture, chances are your business is not at that level. At least not yet. The good news is that most of those companies started with monolithic applications. For smaller software projects, Microservices are just too much to take on. You should better start with modular monolith architecture and transition to full-blown microservices only if you need to.
Contrary to most Microservices examples on the internet, you should break your services by mapping business capabilities instead of entities (i.e., order booking service instead of orders service). You can find more information on this excellent tech talk by Ian Cooper.
2. Horizontal Scaling
One approach that was extremely popular in the past is known as vertical scaling. In essence, if our computer is too slow, we can buy a better one. While this solution works, it usually doesn't last that long. The hardware gradually gets increasingly expensive, and even the most costly machines eventually fail to handle the load. Horizontal scaling is the opposite way of tackling the same problem. Instead of adding more RAM and CPU to an existing machine, we can get more machines. We can scale out if we need more power by spinning up additional servers. If we need to reduce our costs, we can scale in by removing some of them.
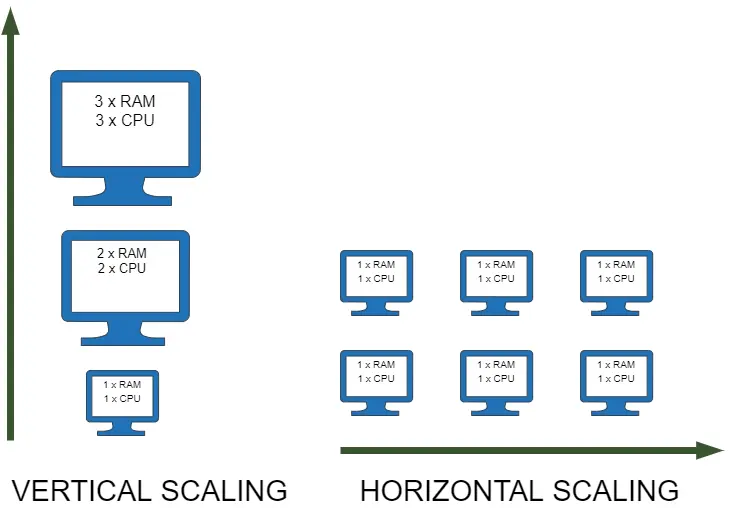
Horizontally scaling web applications usually requires load balancers. A load balancer is a service that sits between clients and servers, routing client requests to maximise performance, usually to the least busy server. At the same time, load balancers can manage sessions, memory, cache, and do all sorts of crazy things (please don't get too crazy with load balancers).
Scaling non-web services horizontally is often not that complicated either. Many messaging queues or streaming platforms are built with this problem in mind. For instance, a top-rated streaming platform Apache Kafka allows partitioning its topics and running up to one consumer service per partition per consumer group. Another widely used messaging broker, RabbitMQ, has a sharding plugin similarly partitioning its queues.
Container orchestrators such as Kubernetes or platforms such as OpenShift make scaling out and scaling in a trivial problem. If you are not familiar with them, you should check them out!
3. Separate Databases for Reading and Writing Concerns
In most user-facing systems the number of data reads is orders of magnitude higher than the number of data writes. We can significantly improve systems like these by copying our data to a separate read-only database and using it to serve data requests. To make this work, we must keep the two databases in sync. One of the most popular ways of synchronizing data relies on the eventual consistency model. This model doesn't guarantee that the data is synchronized immediately. However, it ensures that the data will be consistent sooner or later. Making your systems eventually consistent is a fair price for the ability to scale. It is usually acceptable for most businesses (even though some people might not see it like that at first). If this model is not your cup of tea, you can always rely on good ol' ACID transactions or reading data from the primary database where it must be consistent immediately.
CQRS (Command Query Responsibility Segregation) - this is where it gets interesting. We can go one step further by introducing separate data models for writes (commands) and reads (queries). Instead of synchronizing the same write models, we can aggregate and transform them into models designed for lightning-fast data reads. Moreover, we can pick different database providers and use multiple read databases optimized for specific queries.
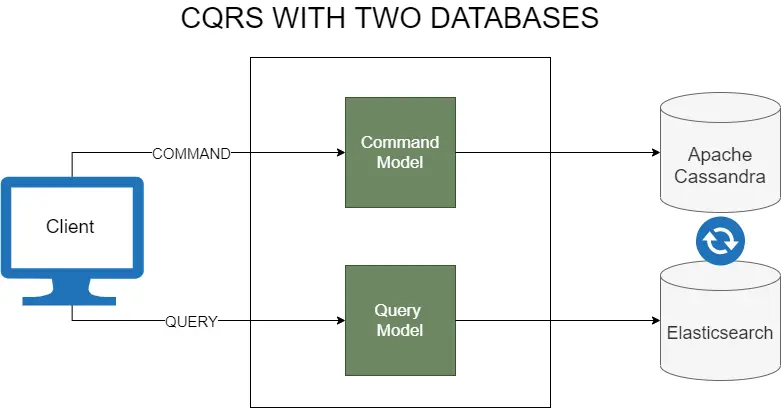
You should use CQRS and separate databases for reading and writing data only for problematic parts of the system. This is not an all-or-nothing approach!
4. Database Sharding
Database sharding is another widely used scaling technique. In short, it's a logical data partitioning based on a selected set of values, often called partition or shard keys. These values should allow us to split the data into multiple autonomous partitions. For instance, we could use database table row values such as customer ID, location, product price, etc. Placing table shards into separate databases running on different servers allows us to reap the benefits of horizontal scaling (number 2 on the list). Moreover, it increases query response times since we only have to search the data within a single shard instead of the full set. We should be cautious when selecting sharding keys to get the most out of database sharding. The sharded partitions must have even data distribution. Otherwise, the largest unbalanced shards will slow our applications down.
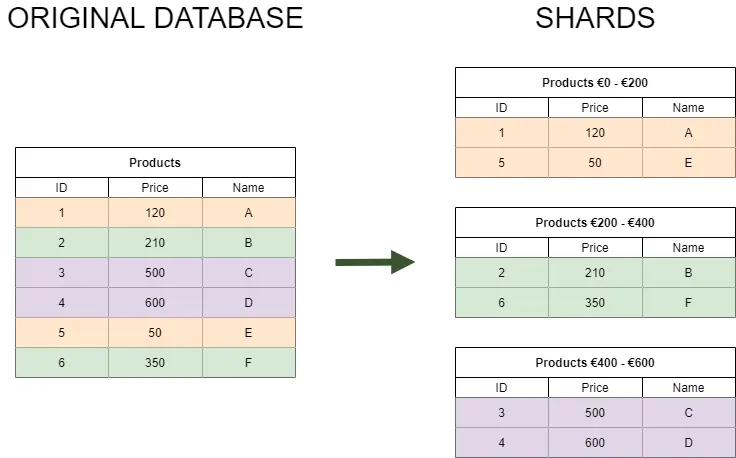
Some database technologies, such as Mongo DB Atlas or MySQL Cluster, include sharding as an out-of-the-box feature.
5. Memory Caching
Memory caching is probably the most well-known way of boosting performance. Sadly, it's not uncommon to overlook it. Caching expensive database queries, sluggish computations, or page renders may work wonders. This is especially true in a world of containers, where multiple service instances produce massive traffic to a single database, often becoming a bottleneck. Caching products like Redis or Memcached make memory caching relatively painless and extremely powerful at the same time.
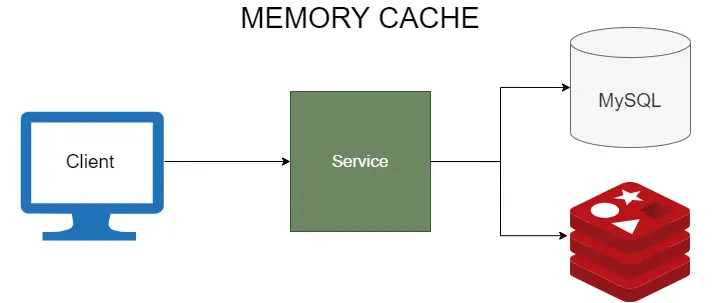
80% of traffic is generated by 20% of requests (or so they say). You should prioritize caching those frequent requests.
6. Going to the Cloud
Technically, going to the cloud isn't a scaling method. On the other hand, it's a game-changer in scaling and saving money. Before the cloud, experts had to guess their capacity needs and purchase everything upfront, leaving plenty of room for mistakes. Modern cloud providers use a pay-as-you-go model that automatically scales our applications when we need it. They can add or remove RAM and CPU by scaling applications up and down vertically. Moreover, they can provide additional servers scaling applications in and out horizontally. The most renowned cloud providers are Amazon Web Services, Google Cloud Platform, and Microsoft Azure.
You should think about how you will deal with unexpected peak demand. Spinning up new servers can take 3-5 minutes, while vertical auto-scaling usually requires some downtime.
Conclusion
Scalability is a tremendously important topic. You may not have to deal with it now, but you should know where to start. The best ways to scale are splitting services, horizontal scaling, separate databases for reading and writing concerns, database sharding, memory caching, and going to the cloud. While each one of those methods is great on its own, combining them will get you to the next level.
Thank you for reading. Is there something else this list is missing? I’d love to hear about your scaling adventures.