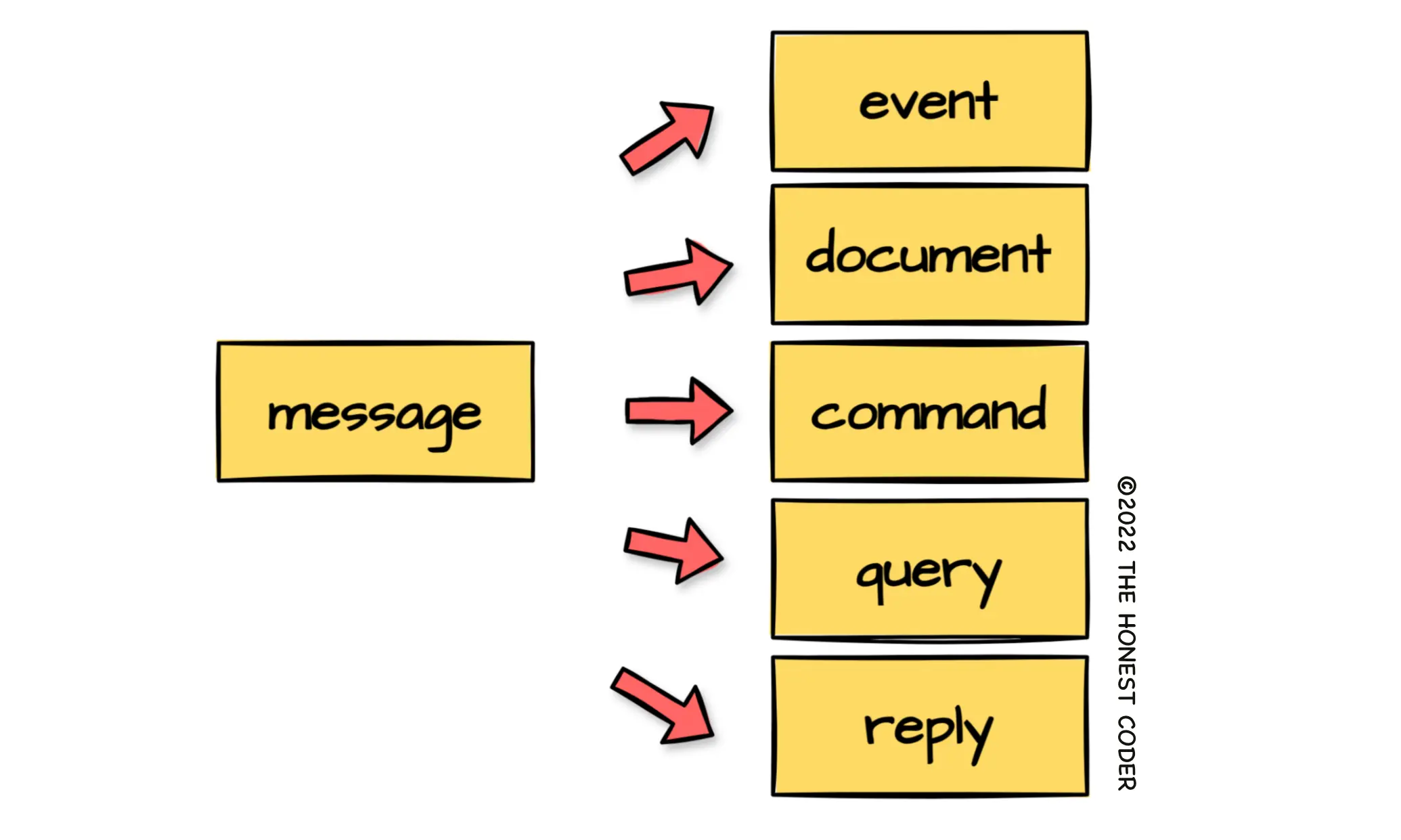
7 Message Metadata Patterns Every Developer Should Know
A message in message-driven systems consists of a payload (aka body) and metadata (aka headers). Message payload has application-specific data. Message metadata describes message payload and provides contextual information. It can also enable multiple message-based service communication patterns, solving common message-driven system challenges. Here are seven message metadata patterns every developer should know.
Message ID
Message ID helps with identifying individual messages. Each message has a unique ID attached to it. Adding message IDs is useful when building idempotent message consumers (read more about idempotence here). Moreover, it enables other metadata patterns, such as causation ID, which will be described later in this article.

Causation ID
Causation ID identifies messages that cause other messages to be published. In simple terms, it's used to see what causes what. The first message in a message conversation typically doesn't have a causation ID. Downstream messages get their causation IDs by copying message IDs from messages, causing downstream messages to be published. Adding causation IDs is especially useful when different messages can cause the same message to be published, i.e., an order cancellation event might be published because a user has decided to cancel the order or because the user's credit card balance was insufficient.

Correlation ID
Correlation ID identifies messages that belong to the same message conversation. The ID is added to the first message and then passed to all downstream messages in the same transaction flow. Combine this pattern with a distributed tracing tool such as Zipkin or Jaeger, and you'll have a solid transaction monitoring and tracing setup.

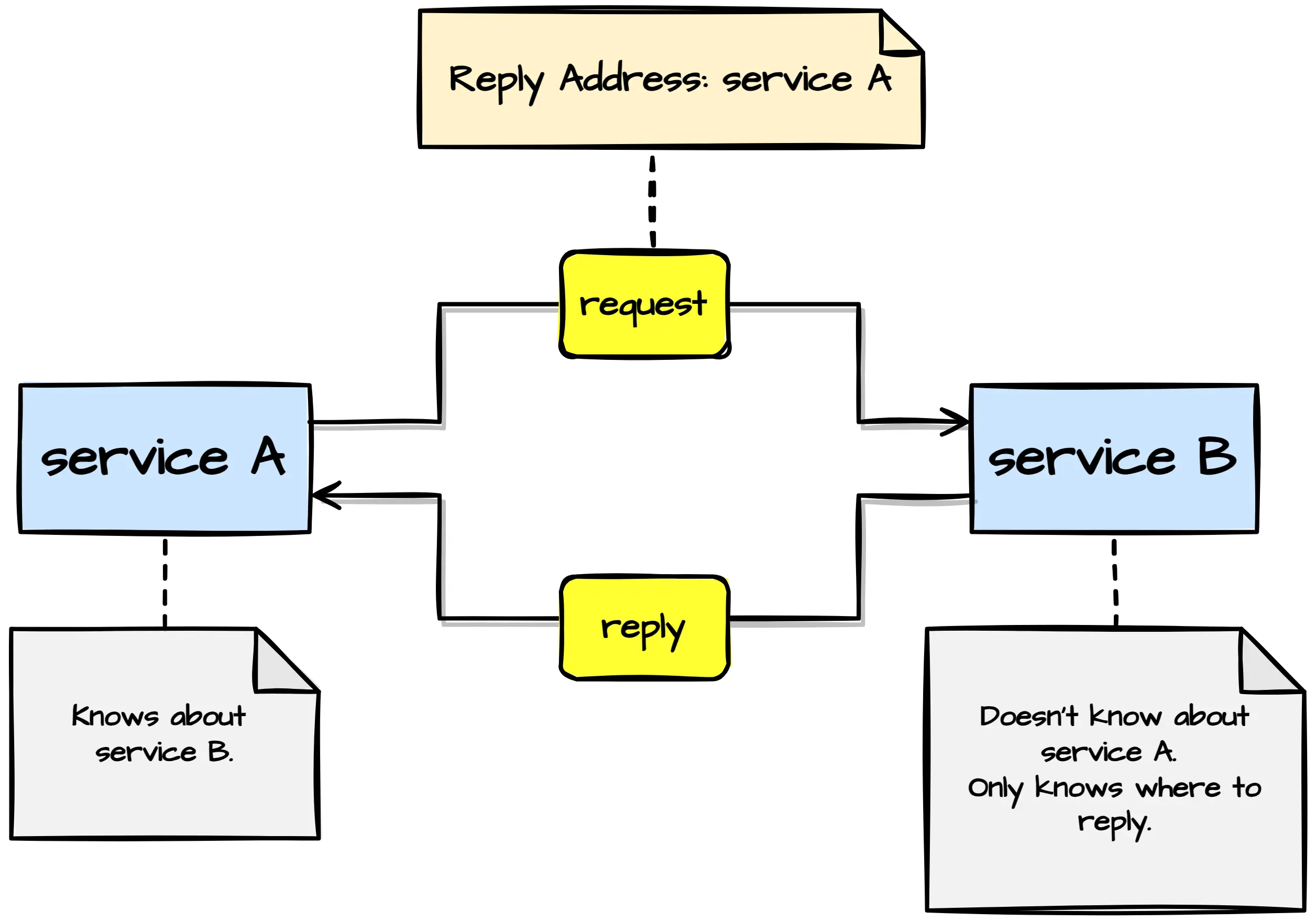
Reply Address
The reply address tells message consumers where to send reply messages. It enables request-reply communication in message-driven systems without strongly coupling message consumers with request message senders.
Message Schema Version
Adding a message schema version helps to deploy breaking message schema changes without or with minimal service downtime. Moreover, publishing multiple versions of the same message for a limited amount of time is very useful when you can't change message consumers and publishers at the same time.

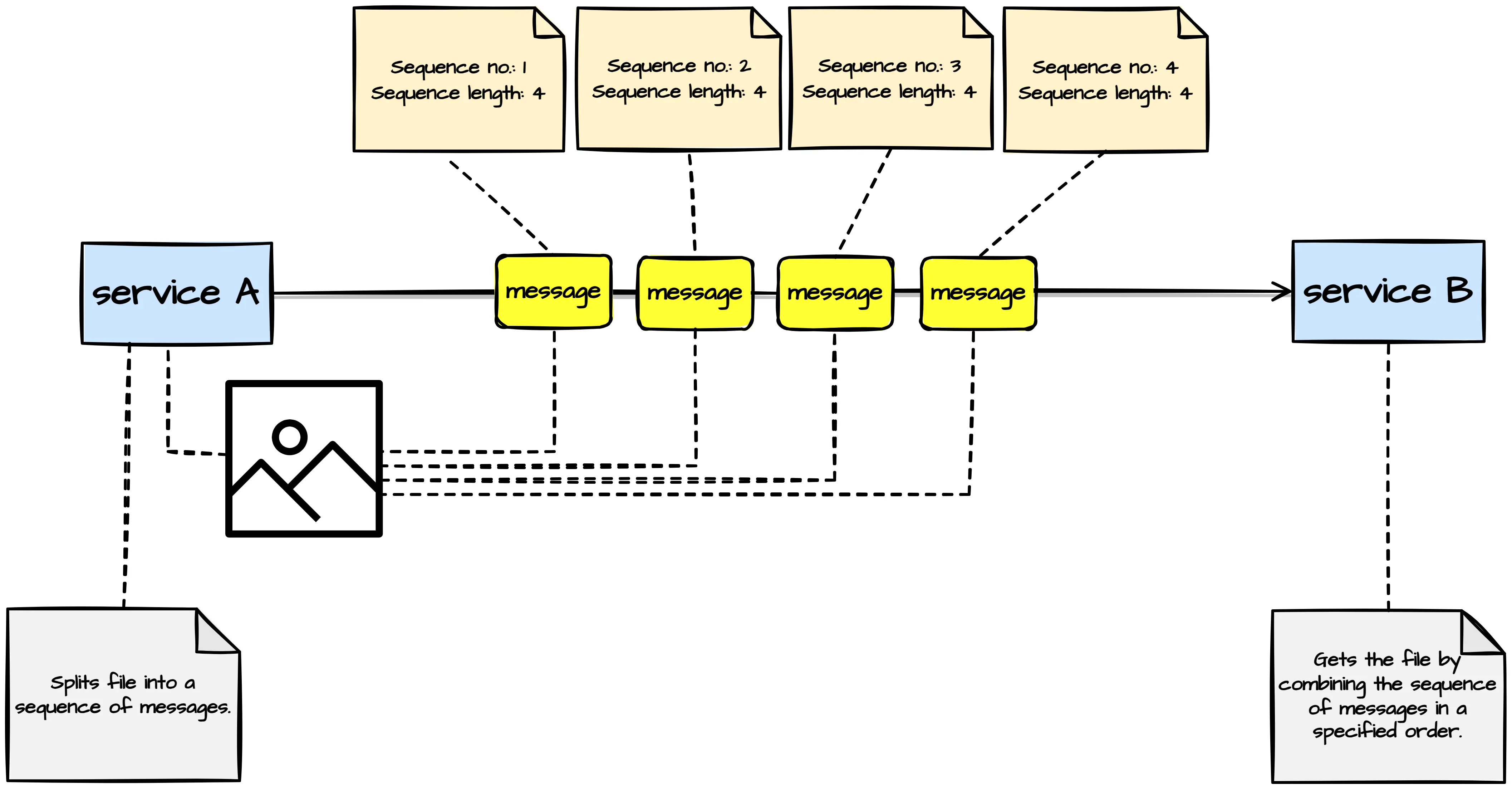
Message Sequence
Message sequence allows transferring an arbitrarily large amount of data using a messaging platform. Before publishing the data, message publishers split it into small chunks, each marked with a sequence number. Message consumers get the data by aggregating consumed messages following the message sequence in the order published.
There are other ways to send large files in message-driven systems. Read more about it here.
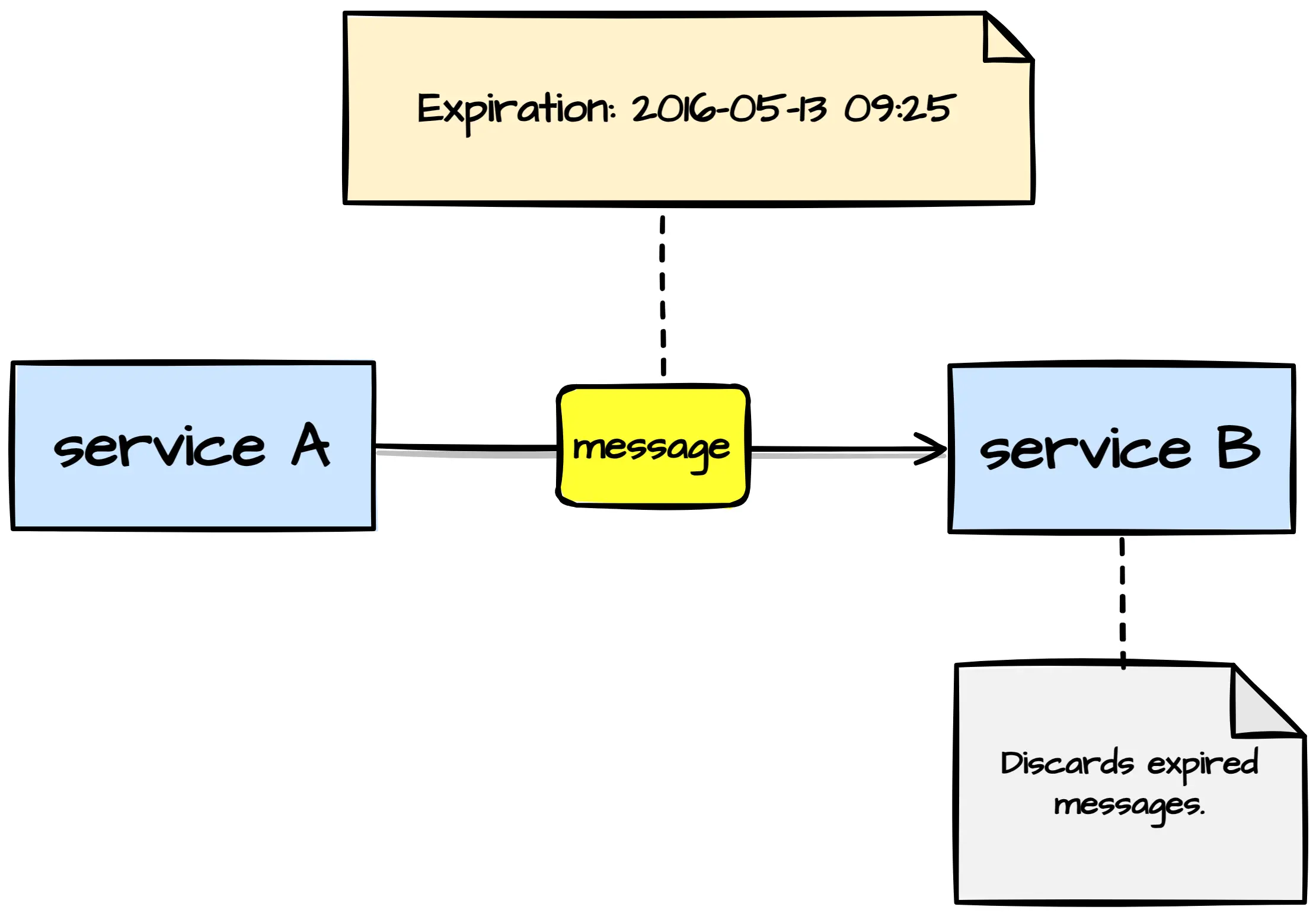
Message Expiration
Some messages are only relevant within a specified timeframe. In those cases, you should introduce message expiration. AMQP-based messaging platforms, more often than not, support message expiration out of the box. However, the same can't be said about stream-based messaging platforms. If you're using a stream-based messaging platform, adding a message expiration metadata field and discarding messages on the consumer's end will do the trick.
Summary
There are quite a few widely used message metadata patterns. They describe popular approaches to optimizing distributed messaging-based systems. You don't have to use all of them, but knowing about them is a significant advantage.
Thank you for reading. Do you know another pattern that this post needs to include? I would love to hear about it in the comments.