Building Multilingual Relational Databases: Approaches and Tradeoffs
If you talk to a man in a language he understands, that goes to his head. If you talk to him in his language, that goes to his heart.
- Nelson Mandela
Building software applications for global audiences is challenging. One critical aspect that software engineers have to consider is making these applications speak different languages. A widely used approach is to use translated resource files. However, moving them to a database might be a good alternative for cases where you need to make translations more dynamic. There are multiple ways of building multilingual relational databases. Yet, one must understand both the approaches and the tradeoffs before starting.
Denormalizing Translations as Columns
A straightforward way to build multilingual relational databases is to add denormalized translation columns for each supported language.
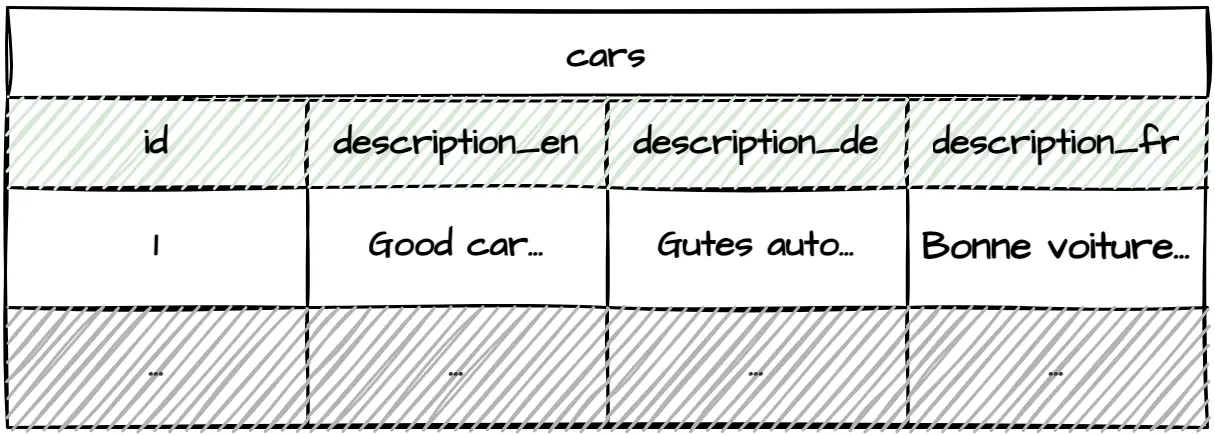
This approach is lightning-fast to implement. It provides a significant advantage over the other approaches when you want to release your application as quickly and cheaply as possible. Moreover, it makes queries easy to understand and super quick to execute since it doesn't introduce additional joins.

However, this approach works best only if you have a few tables to translate and the small number of languages you wish to support is not likely to change. Adding additional language requires modifying tables. Furthermore, it requires changing all relevant database queries. It's possible to avoid changing queries manually by making them dynamic, but it comes with its own cost of maintainability and potential runtime issues.
Serializing Translations
Another approach is to serialize translations into a single field. Unlike the previous method, it allows adding additional language support without modifying tables. JSON and XML are the most popular serialization formats since most relational databases provide ways of querying the data directly from JSON/XML fields.
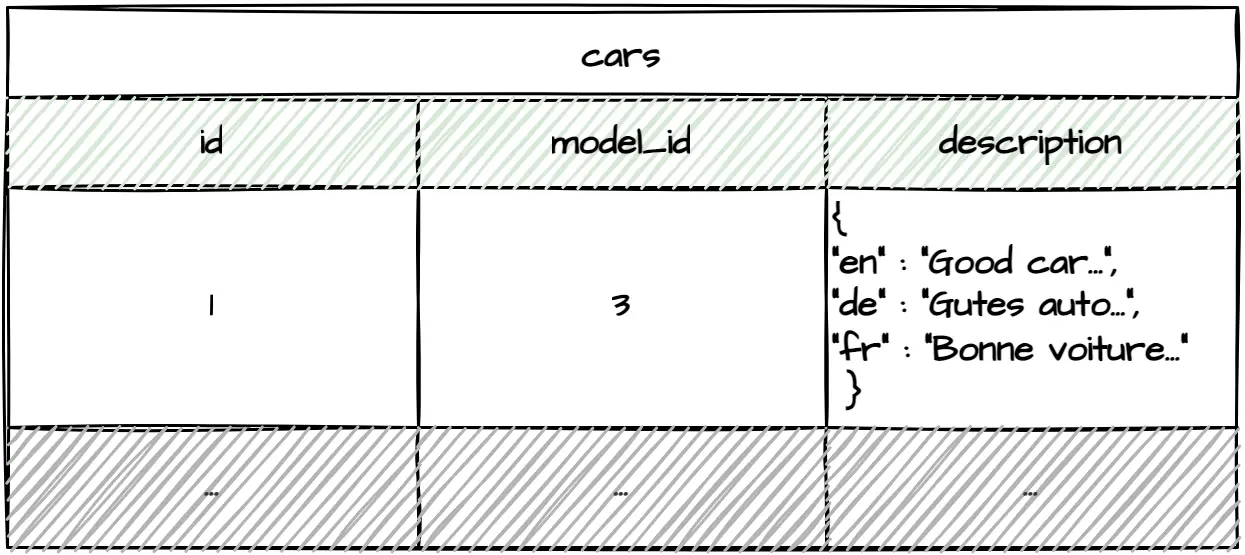
The problem, however, is that different RDBMS implementations have different ways of querying the data. As a result, it couples queries to a concrete RDBMS implementation. Not to mention that additional JSON/XML parsing adds overhead which might slow down your application. Did I mention that thinking about importing translations into serialization-based multilingual applications automatically makes me roll up my sleeves?

This approach could work for small applications that have little to translate and are coupled with concrete RDBMS implementations.
Building Shared Translation Tables
Creating shared translation tables is a more scalable approach to building multilingual relational databases. Unlike the previously listed methods, it allows adding translations without adjusting the original table.
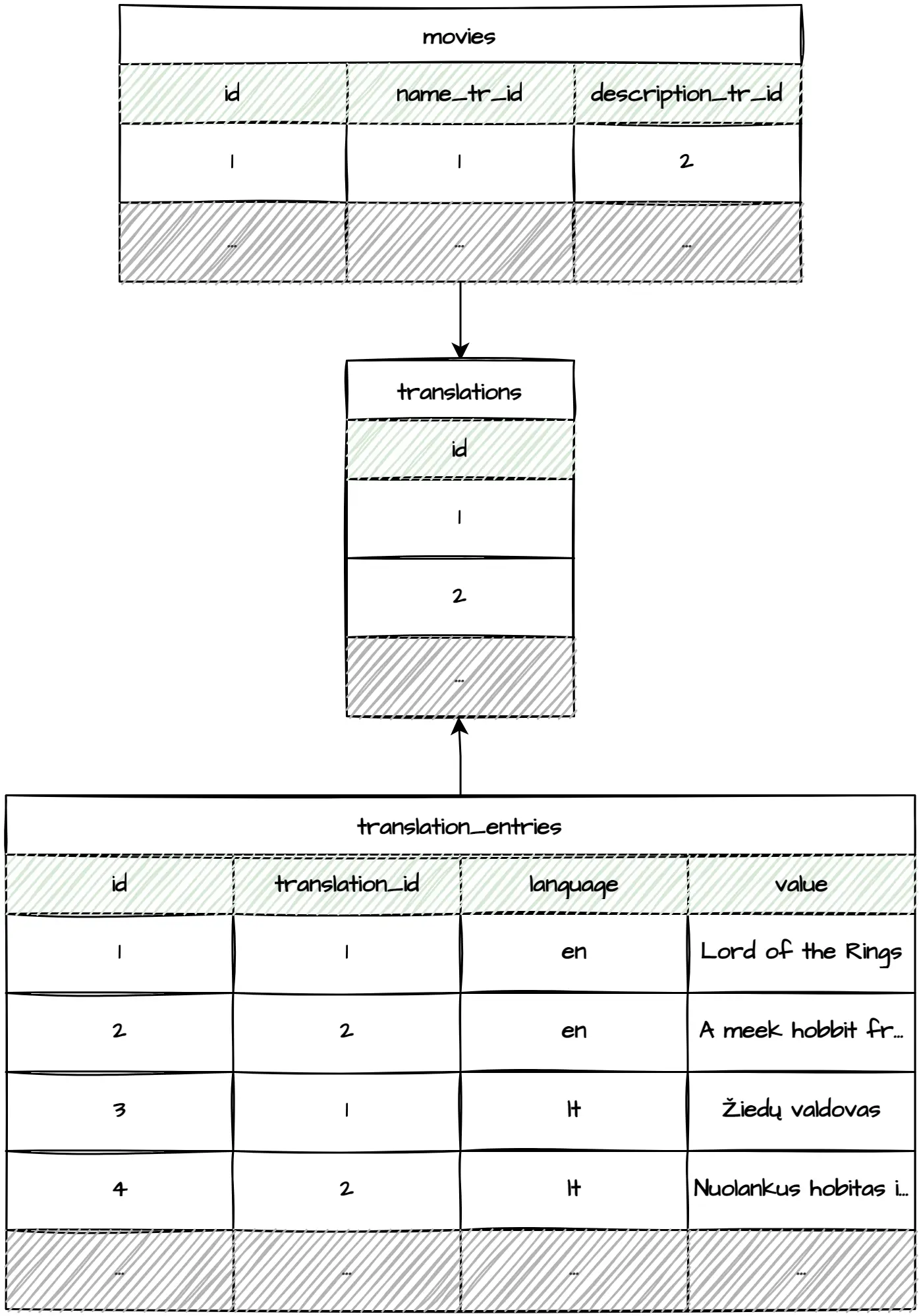
Having all the translations in a single place makes managing it remarkably easy. Additionally, importing and exporting translations as a single file is child's play, which becomes relevant when outsourcing translation services.

While close to being ideal, this approach has some severe drawbacks. The biggest one is having to execute n table joins for n translatable fields for x tables being translated. And you better hope that you won't need user-specific translations, which would result in even more table joins. This is a significant overhead!
Another drawback is that translatable tables have foreign key references to the translations table. This complicates deleting and reinserting translations, which is common while importing data.
Building Entity Translation Tables
Building a separate table for each translatable entity is another flexible approach. It requires only one join on n translatable fields, eliminating the join hell described previously. As a bonus, this approach has no problems deleting or reinserting translations.
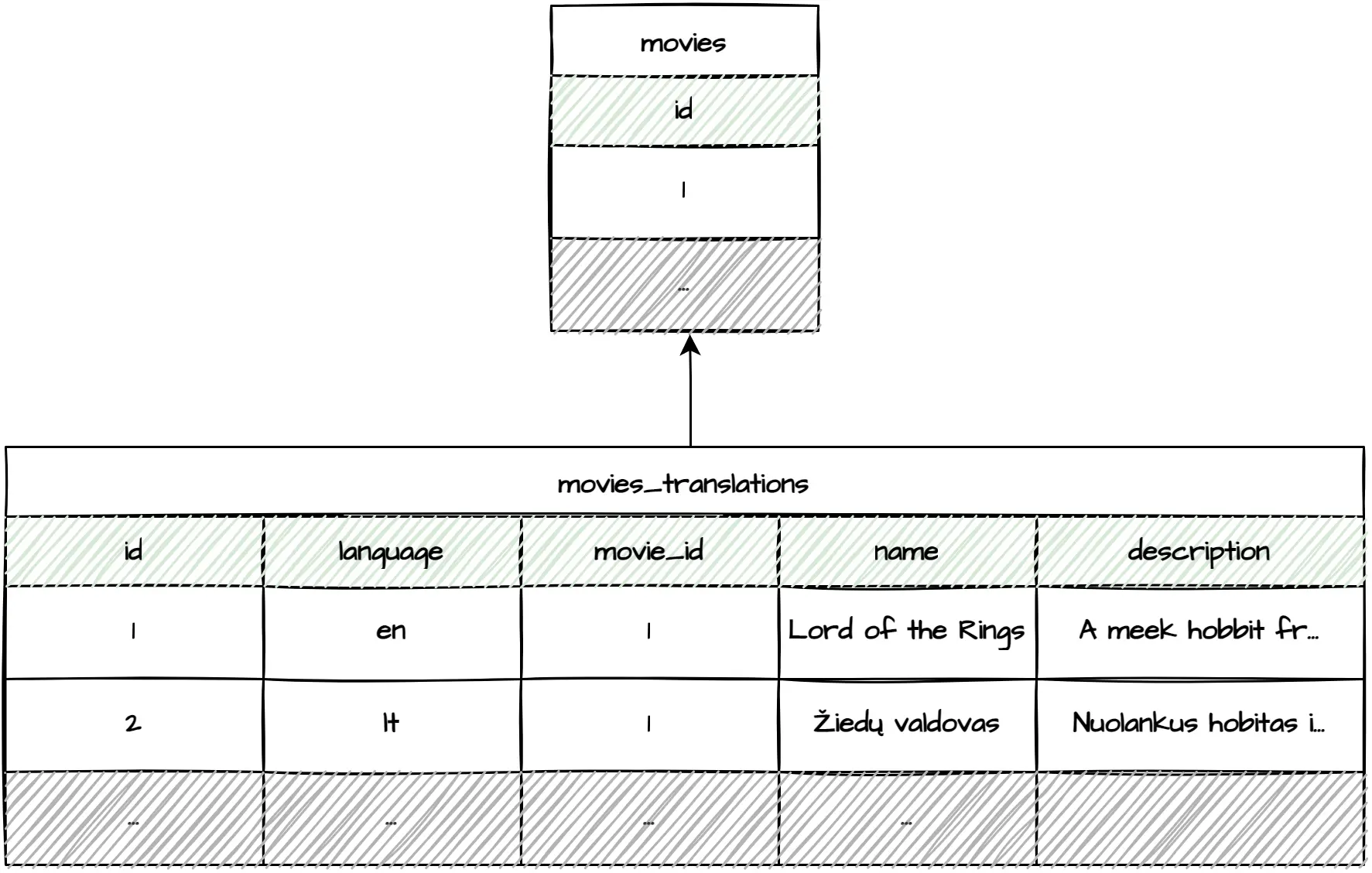
The benefits, however, come with the burden of building and maintaining many entity translation tables.
Translating Labels
If your multilingual application is not a purely data-driven API, the whole system, including labels, buttons, etc., will likely need to be translated. The entity translation tables approach described above could be utilized by creating tables such as buttons and buttons_translations. However, that would make adding and maintaining translations unnecessarily complex. A simpler solution is to create a table dedicated solely to generic translations.
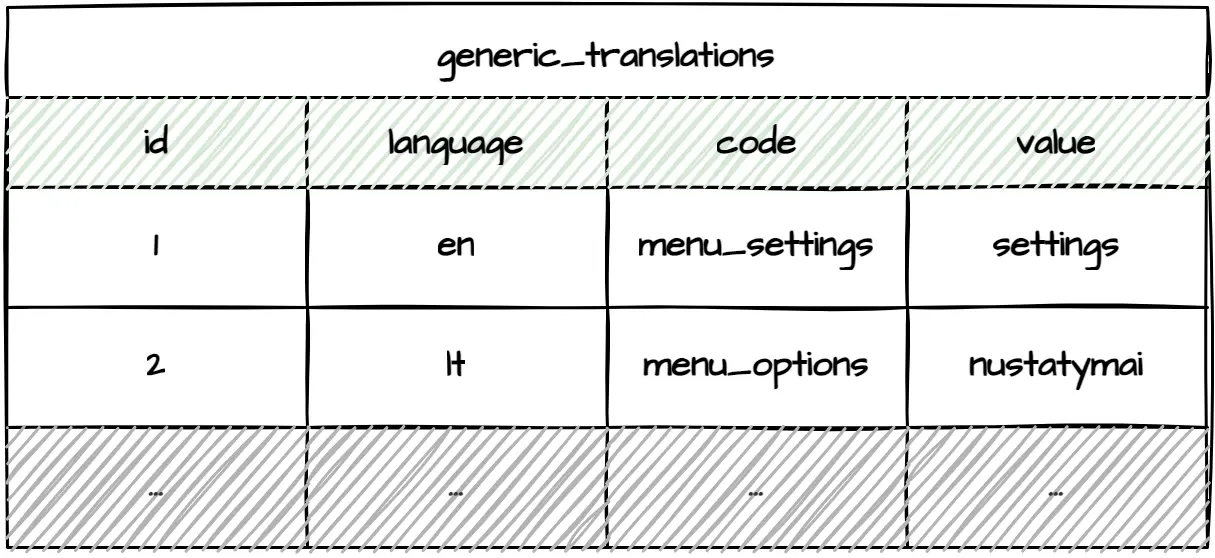
The generic_translations table becomes incredibly close to a generic key-value store. If necessary, you could move these translations to any NoSQL key-value store and share them between multiple applications.
Building a Table for Languages
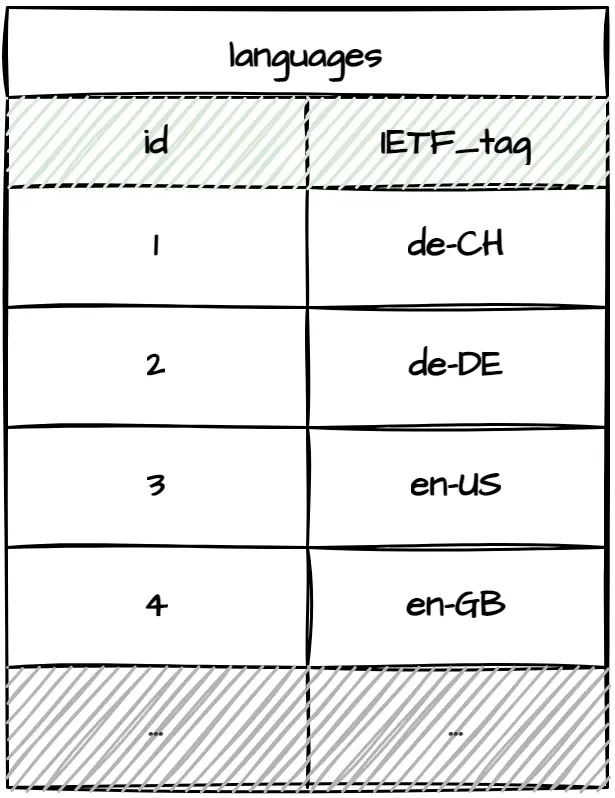
Notice that all the table examples above use ISO two-letter language codes (de, en, etc.) instead of having foreign key references to an additional languages table. This approach works well since country codes can be used as natural keys to avoid additional language lookups. Moreover, it's extremely unlikely for language codes to change. However, ISO two-letter language codes do not cover all edge cases. Using ISO IETF language tags instead would make sense if you had to support multiple language cultures such as en-US/en-GB (color vs colour), de-CH/de-DE (ss vs ß), etc. Now, suppose you were dealing with public or legal domains. In that case, it could also make sense to use IANA language tags such as de-1901 and de-1996 since there was an orthography reform in 1996 or az-Arab and az-Cyrl since in 1991 Azerbaijan's parliament voted to replace the Cyrillic alphabet with Latin. If you aren't sure whether you'll need to support these language differences or would rather be safe than sorry, going for a separate table for languages is probably not a bad idea.
Ensuring Fallback
It's a good idea to build a language fallback mechanism in case some translations are missing, whether in English or any other preferred language. One way to do it is to configure the fallback mechanism in stored procedures. Unfortunately, it's a lot of work if you have separate entity translation tables since you must build stored procedures for each one of them. Another option is to configure the fallback directly in your application. It'll do the trick but may require additional database calls. Finally, you could keep default translations in entity tables.
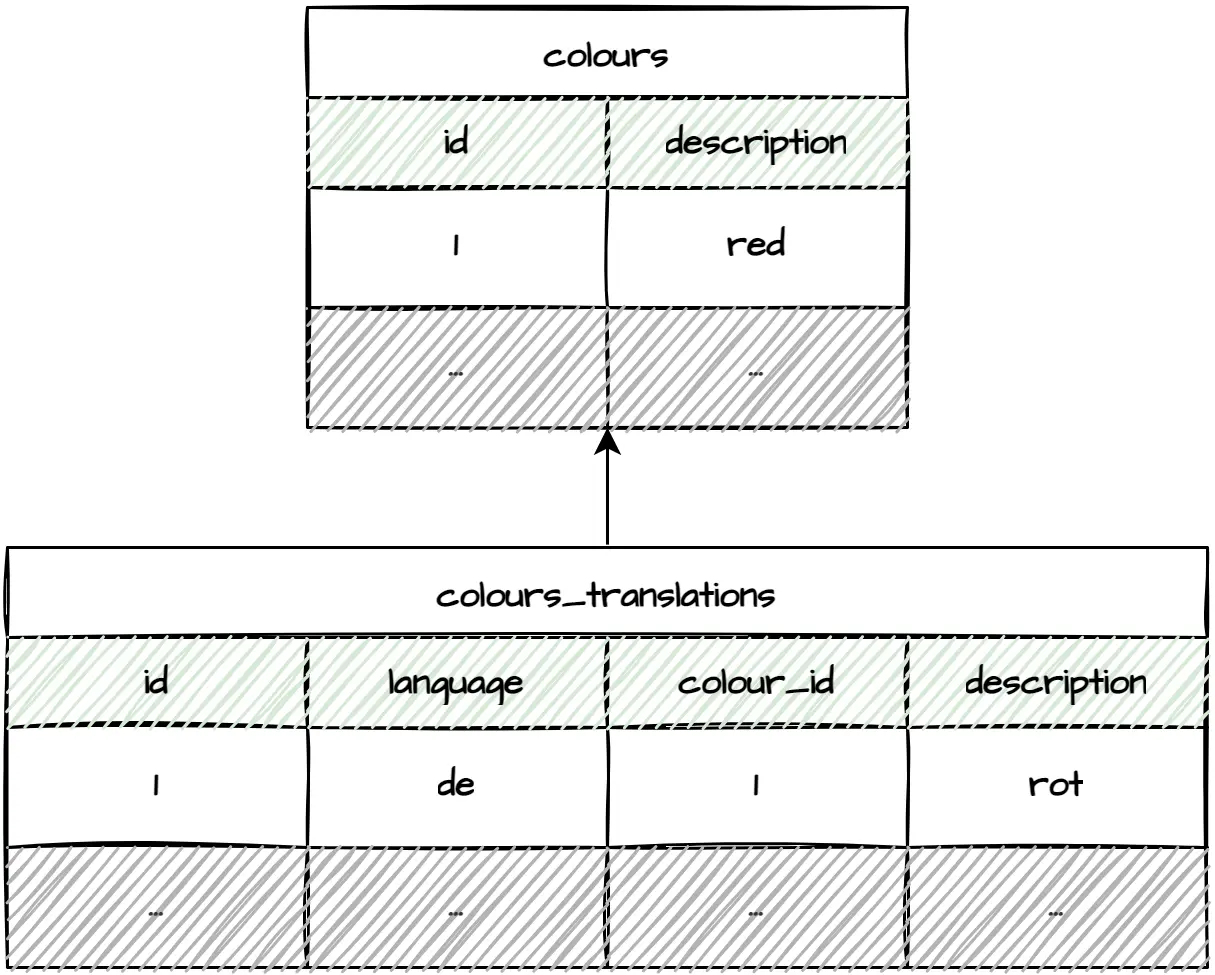
This approach keeps queries small and applications simple and, as a bonus, provides additional context when working with entities directly in the database. While changing the default language might be a bit of work, I wouldn't worry too much since it doesn't happen that often.
Final Words
There are numerous aspects to consider when building multilingual applications. Translation storage solutions might differ based on application size, content, rate of change, languages or even some exotic requirements. Sometimes translated resource files work the best. Other times you have to go the multilingual relational database route. To keep it simple, you might denormalize translations as columns or serialize them as JSON. To make it flexible, you could introduce separate entity translation tables or put everything in a shared place. Moreover, there could be cases where you must combine multiple approaches to reach the desired goal. One thing is sure - the more solutions you consider, the better ones you pick.
Thank you for reading. This is my first blog post with hand-drawn pictures. Did you like them? Would you like to see more of them? I'd love to hear your thoughts.

