
Choosing the Right Database
To SQL, or not to SQL, that is the question.- William Shakespeare (I think)
Choosing the right database is a crucial task for most software systems. The good news is that there's no magic involved.
CAP
CAP theorem, also known as Brewer's theorem, is fundamental to understand and one of the first things we must consider when choosing a database. In a nutshell, any distributed database system can only provide two of the three CAP guarantees: Consistency, Availability, and Partition tolerance.
Consistency
Every request receives the most recent data. Consistency is guaranteed by updating all nodes with the same data before allowing further reads.
Availability
Every request receives a response. However, responses might not contain the most recent data. Availability is guaranteed by replicating the data across multiple servers.
Partition Tolerance
The system continues to work despite messages being dropped by the network between nodes. Partition tolerance is guaranteed by replicating data across combinations of nodes and networks.
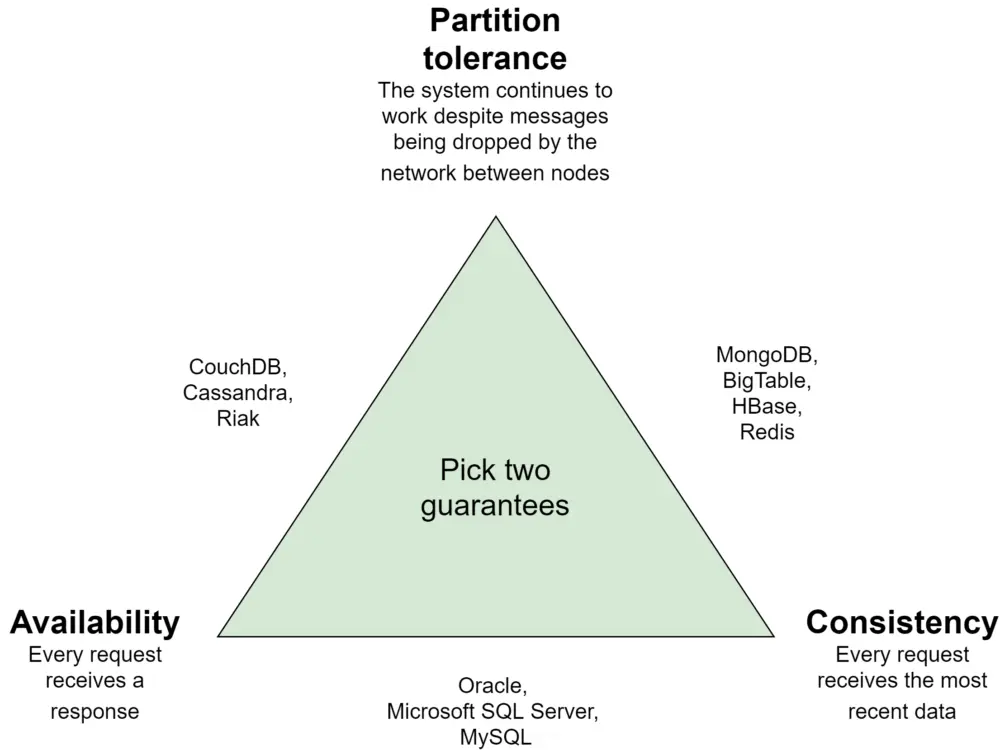
In practice, the lines between actual database providers and their CAP guarantees can become blurry. Many modern databases can be configured to be either CA, CP, or AP.
When dealing with distributed systems, we should expect network partition failures. Therefore, we must tolerate network partitioning. That leaves us with a choice between availability and consistency. Nevertheless, when no network partition failures are present, both availability and consistency can be satisfied.
The PACELC theorem goes even further down the theoretical computer science rabbit hole. It extends the CAP theorem by stating that another trade-off between latency and consistency arises in the absence of network partitions.
SQL
SQL (relational) databases store data in tables with predefined schemas. These schemas can be changed later, but doing so requires modifying the whole database and some downtime. Each table row contains all the information about one entity, while each column contains all the separate entity fields. The data can be manipulated using SQL (structured query language).
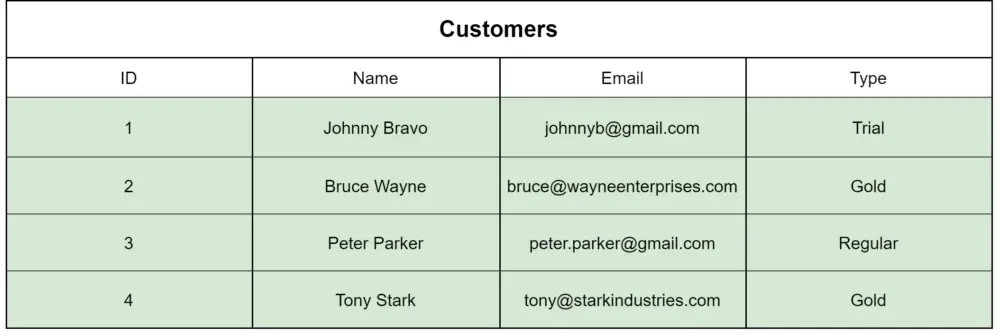
Regarding the CAP theorem, most distributed relational database systems choose consistency over availability. This choice allows SQL databases to be ACID compliant, making them the most reliable option for data and transactional guarantees. However, this also means that SQL database systems aren't accessible when the network connections are down.
Some of the most well-known relational databases are Oracle, Microsoft SQL Server, MySQL, PostgreSQL, MariaDB, and SQLite.
When to Use SQL
- Data reliability and ACID compliance are more important than scalability and processing speed.
- Your data has a clearly defined structure that's unlikely to change.
- Your business isn't expecting massive growth in traffic volume.
NoSQL
NoSQL (non-relational) databases are unstructured. They support dynamic data schemas, which can be changed on the fly. The data can be manipulated using syntax that is different for each NoSQL database. In 2011, collaborative efforts were made to create a common query language specification for NoSQL - UnQL (unstructured query language). However, it didn't last long - in 2012, the UnQL project was put on hold.
When it comes to the CAP theorem, the vast majority of distributed non-relational database systems are designed around the BASE philosophy and choose availability over consistency. They may not have ACID guarantees or contain up-to-date data, but boy are they fast.
The main NoSQL data storage models are key-value, document, wide-column, and graph.
Key-Value
Key-value databases store data in an array of key-value pairs. Key-value databases don't know anything about the stored values. Therefore, they're used when simple data queries by key are sufficient.
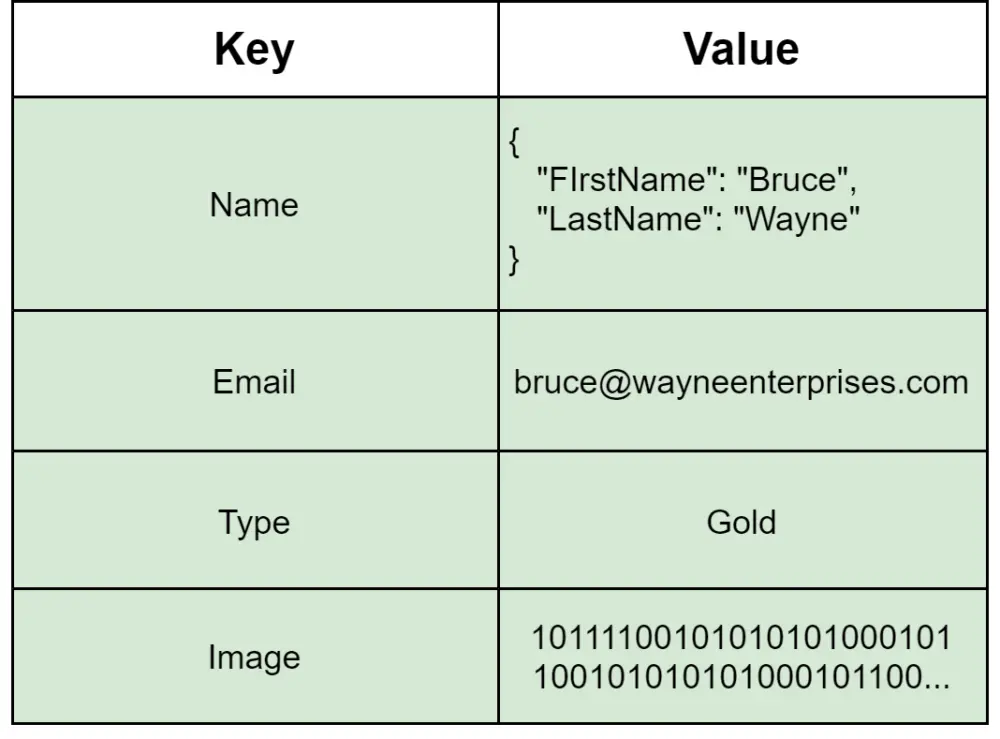
Redis, Amazon DynamoDB, Amazon S3, and Voldemort are some of the most well-known key-value databases.
Document
Document databases store data in documents that can have unique structures. Documents are grouped in collections. Document databases allow defining secondary indexes, as they are aware of the document structure. Therefore, they're frequently used when search capabilities beyond key lookup are needed.
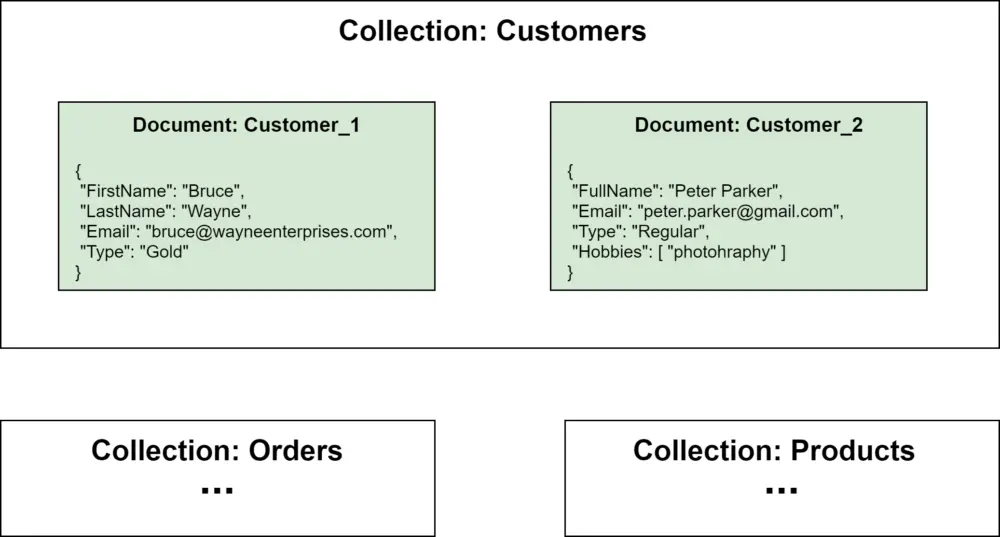
Some of the most well-known document databases are MongoDB, Amazon DocumentDB, Amazon DynamoDB, and CouchDB.
Wide-Column
Wide-column databases store data in column families that act as containers for rows. Wide-column databases are often used for analyzing big datasets.
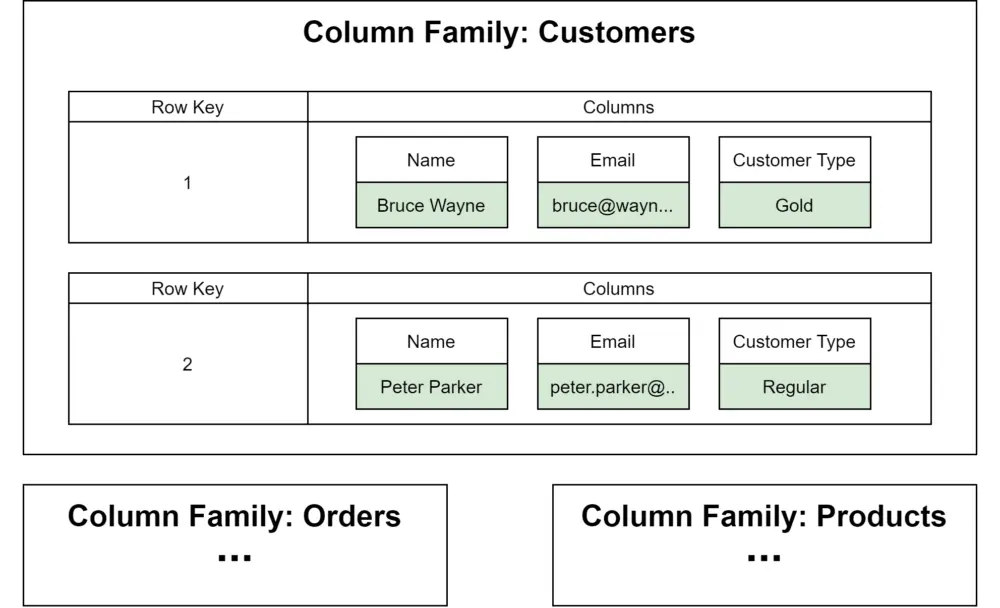
Some of the most well-known wide-column databases are Cassandra and HBase.
Graph
Graph databases store data in graph structures with nodes representing entities, properties representing information about entities and lines representing connections between entities. Graph databases store entities whose relationships are best represented in a graph.
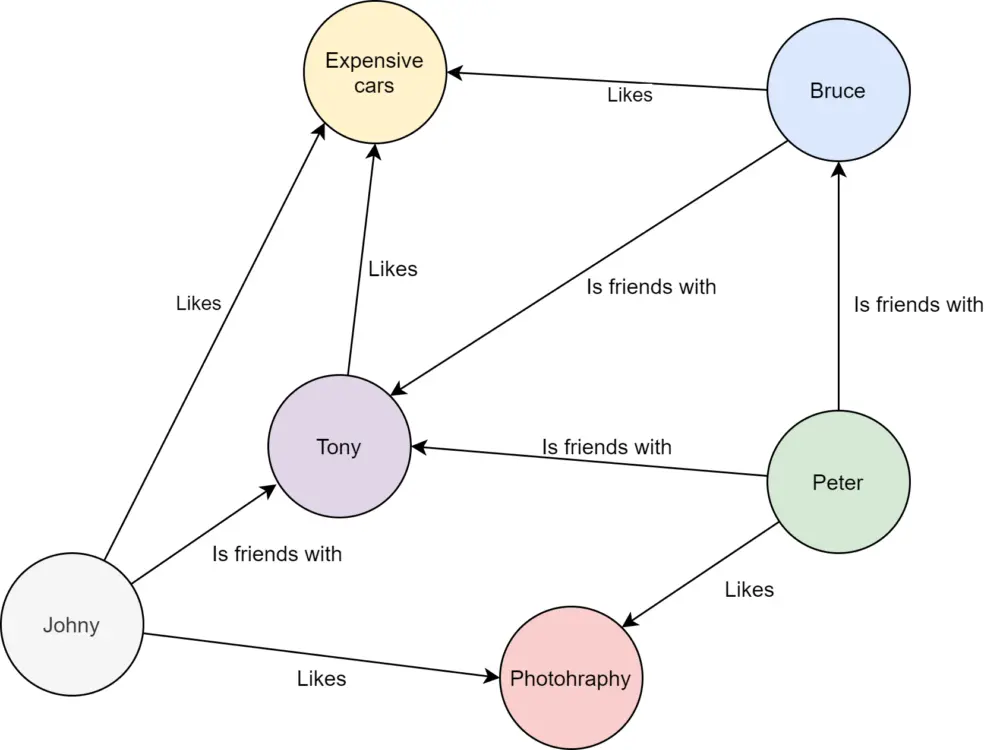
Some of the most well-known graph databases are Neo4J, JanusGraph, and InfiniteGraph.
When to Use NoSQL
- Scalability and processing speed are more important than being ACID-compliant.
- You have large amounts of data with little to no structure.
- The system is rapidly developing, and the data structure is frequently changing.
Thank you for reading. Is there something missing from this guide? If so, please leave a comment.


