Are Code Reviews Killing Your Delivery Speed?
Discover 3 strategies you can implement now to ensure no code review will slow you down.
Software engineering and technical leadership blog.
Discover 3 strategies you can implement now to ensure no code review will slow you down.

4 reasons why I switched from WordPress to Publii.

From creating chaos with endless meetings to enforcing inefficient processes, learn the art of subtle sabotage!

Learn to implement Domain-Driven Design patterns using Entity Framework Core 8!
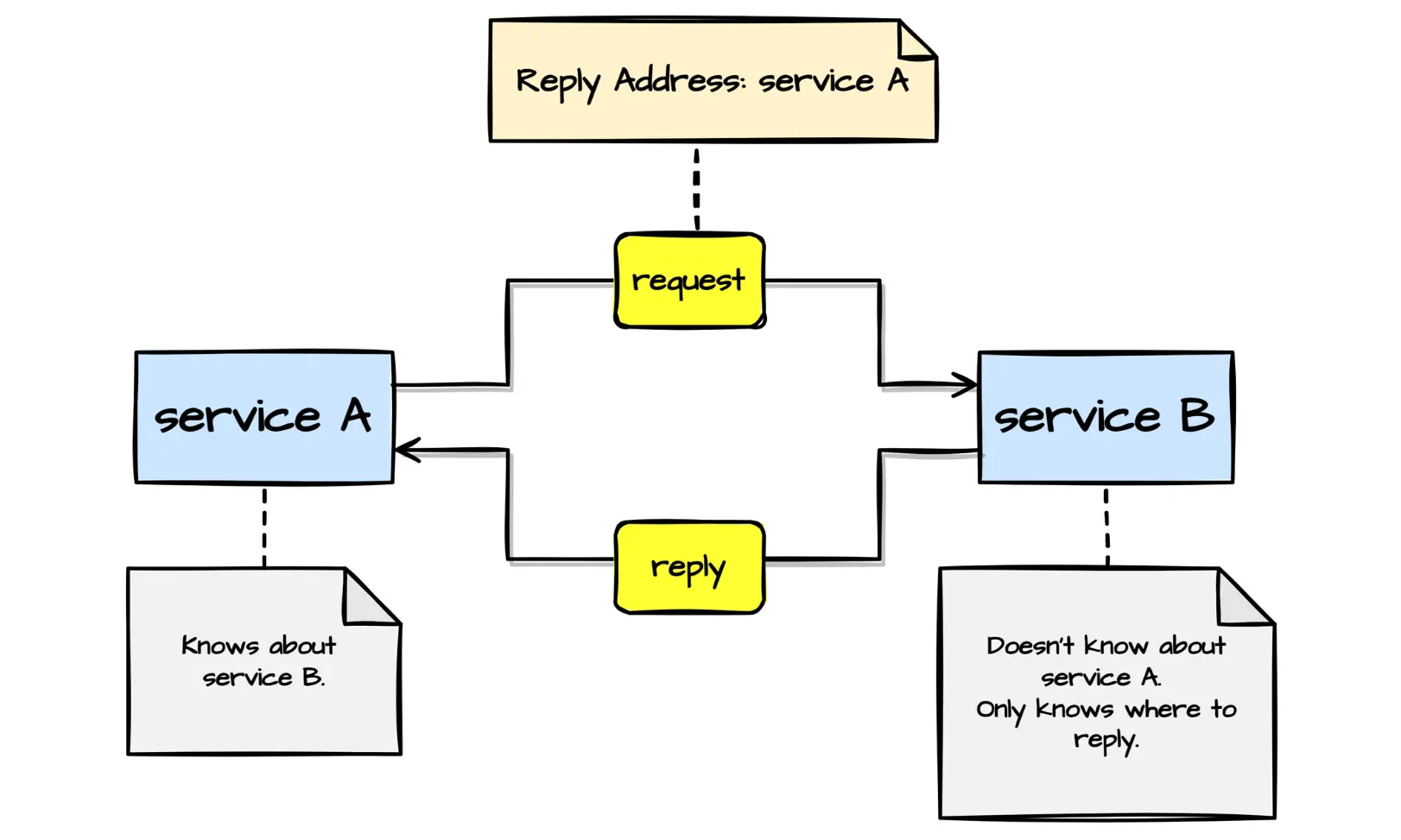
Every developer working with message-driven systems should know these seven message metadata patterns.

How to share large files when building message-driven systems dealing with image recognition, video processing, or big data analysis.
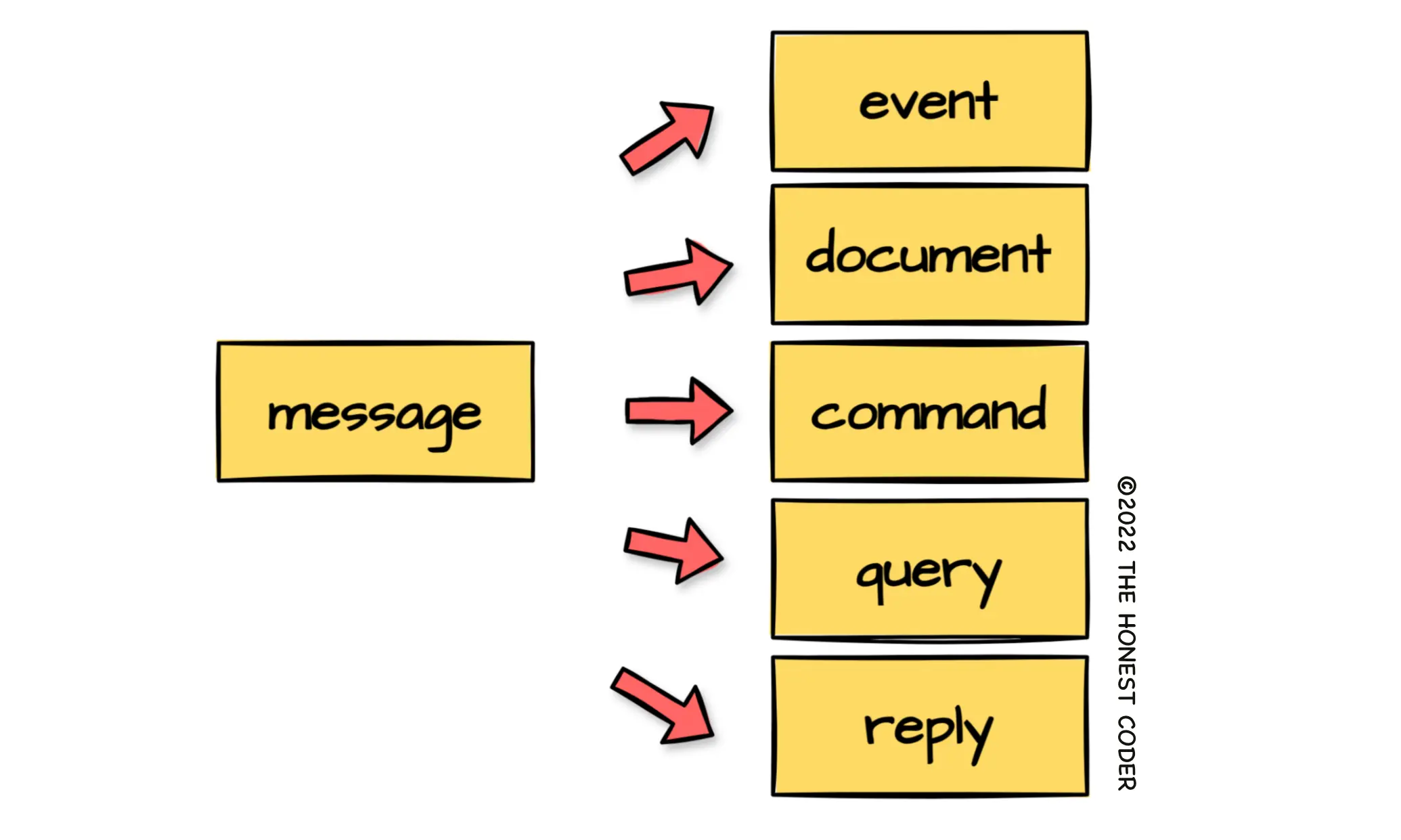
Abusing message types in message-driven systems may result in bloated messages, unclear intent, or impossible-to-understand data flows.

Learn to design and build multilingual software applications for global audiences.

